
EVM Deep Dives: The Path to Shadowy Super Coder 🥷 💻 - Part 4
Under The Hood - Storage Opcodes In the Go Ethereum (Geth) Client

This is the fourth installment in the “EVM Deep Dives” series. In Part 3 we did a deep dive into contract storage, I now want to show you how an individual contract’s storage fits into the wider “World State” of the Ethereum chain.
To do this we’re going to inspect the Ethereum chain architecture, its data structures and peer inside the internals of the “Go Ethereum” (Geth) client.
We’ll start with the data contained in an Ethereum block and work backward to a specific contract’s storage. We’ll finish by taking a look at the SSTORE & SLOAD opcodes implementations in Geth.
This will serve multiple purposes. It will introduce you to the Geth codebase, teach you about the Ethereum “World State” and further your overall understanding of the EVM.
Ethereum Architecture
We’ll start with the image below. Do not be intimidated, by the end of this article you’ll understand exactly how this all fits together. This represents the Ethereum architecture and the data contained within the Ethereum chain.

Rather than look at the diagram as a whole we’ll analyse it piece by piece. For now, let’s focus on the “Block N Header” and the fields it contains.
Block Header
The Block Header contains the key information about an Ethereum block. Below is the “Block N Header” snippet along with its data fields. Take a look at this block 14698834 on etherscan and see if you can see some of the fields in the diagram.

The block header contains the following fields:
Prev Hash - Keccak hash of the parent block
Nonce - Used in proof of work computation
Timestamp - Scale value of the output of UNIX time( )
Uncles Hash - Keccak hash for uncled blocks
Beneficiary - Beneficiary address, mining fee recipient
LogsBloom - Bloom filter of two fields, log address & log topic in the receipts
Difficulty - Scalar value of the difficulty of the previous block
Extra Data - 32 byte data relevant to this block
Block Num - Scalar value of the number of ancestor blocks
Gas Limit - Scalar value of the current limit of gas usage per block
Gas Used - Scalar value of the total gas spent on transactions in this block
Mix Hash - 256-bit value used with a nonce to prove proof of work computation
State Root - Keccak Hash of the root node of state trie (post-execution)
Transaction Root - Keccak Hash of the root node of transaction trie
Receipt Root - Keccak Hash of the root node of receipt trie
Let’s see how these fields map to what is in the Geth client codebase. We’ll look at the “Header” struct defined in block.go which represents a block header.

We can see the values stated within the codebase match our conceptual diagram. Our goal is to get from the block header down to the storage of an individual contract.
To do so we need to focus on the “State Root” field of the block header highlighted in red.
State Root
The “State Root” acts like a merkle root in that it is a hash that is dependent on all the pieces of data that lie underneath it. If any piece of data changes the root will also change.
The data structure underneath the “State Root” is a Merkle Patricia Trie which stores a key-value pair for every Ethereum account on the network, where the key is an Ethereum address and the value is the Ethereum account object.
In actuality, the key is the hash of the Ethereum address and the value is the RLP encoded Ethereum account however we can ignore this for now.
Below is the section of the “Ethereum Architecture” diagram that represents the Merkel Patricia Trie for the “State Root”.

The Merkle Patricia Trie is a non-trival data structure so we won’t deep dive into it in this article. Instead, we can instead keep the key-value mapping model of address to the Ethereum account.
If you are interested in the Merkle Patricia Trie I recommend checking out this excellent introductory article.
Next, let’s inspect the Ethereum account value that the Ethereum addresses are mapping to.
Ethereum Account
The Ethereum account is the consensus representation for an Ethereum address. It is made up of 4 items.
Nonce - Number of transactions made by the account
Balance - Balance of the account in Wei
Code Hash - Hash of the bytecode stored in the contract/account
Storage Root - Keccak Hash of the root node of storage trie (post-execution)
We see these in this snippet from the original Ethereum architecture image.

Again we can jump into the Geth codebase and find the corresponding file state_account.go and the struct that defines an “Ethereum account” referred to as a StateAccount.

Again we can see the values stated within the codebase match our conceptual diagram.
Next, we need to zoom in on the “Storage Root” field within the Ethereum account.
Storage Root
The storage root is much like the state root in that underneath it is another Merkle Patricia trie.
The difference is that this time the keys are the storage slots and the values are the data in each slot.
Again in actuality, there is RLP encoding of the values & hashing of the keys that goes on as part of this process.
Below is the section of the “Ethereum Architecture” diagram that represents the Merkel Patricia Trie for the “Storage Root”.

As before the “Storage Root” is a merkle root hash that will be impacted if any of the underlying data (contract storage) changes.
Any change in contract storage will impact the “Storage Root” which in turn will impact the “State Root” which in turn will impact the “Block Header”.
At this stage of the article, we’ve achieved our goal of taking you from an Ethereum block down to an individual contract’s storage.
The next part of the article is a deep dive into the Geth codebase. We will look briefly at how the contract storage is initialised and what happens when the SSTORE & SLOAD opcodes are called.
This will help you make the mental connections from what we’ve discussed so far back to your solidity code and the underlying storage opcodes.
A warning, the next section is heavy on the code side and assumes the ability to read code
StateDB → stateObject → StateAccount
To get us started we need a brand new contract. A brand new contract means a brand new StateAccount.
Before we start there are 3 structures we’re going to be interfacing with:
StateAccount
StateAccount is the Ethereum consensus representation of “Ethereum accounts”.
stateObject
stateObject represents an “Ethereum account” that is being modified.
StateDB
StateDB structs within the Ethereum protocol are used to store anything within the merkle trie. It's the general query interface to retrieve: Contracts & Ethereum Accounts
Let’s look at how these 3 items are interconnected and how they relate back to what we have been discussing.
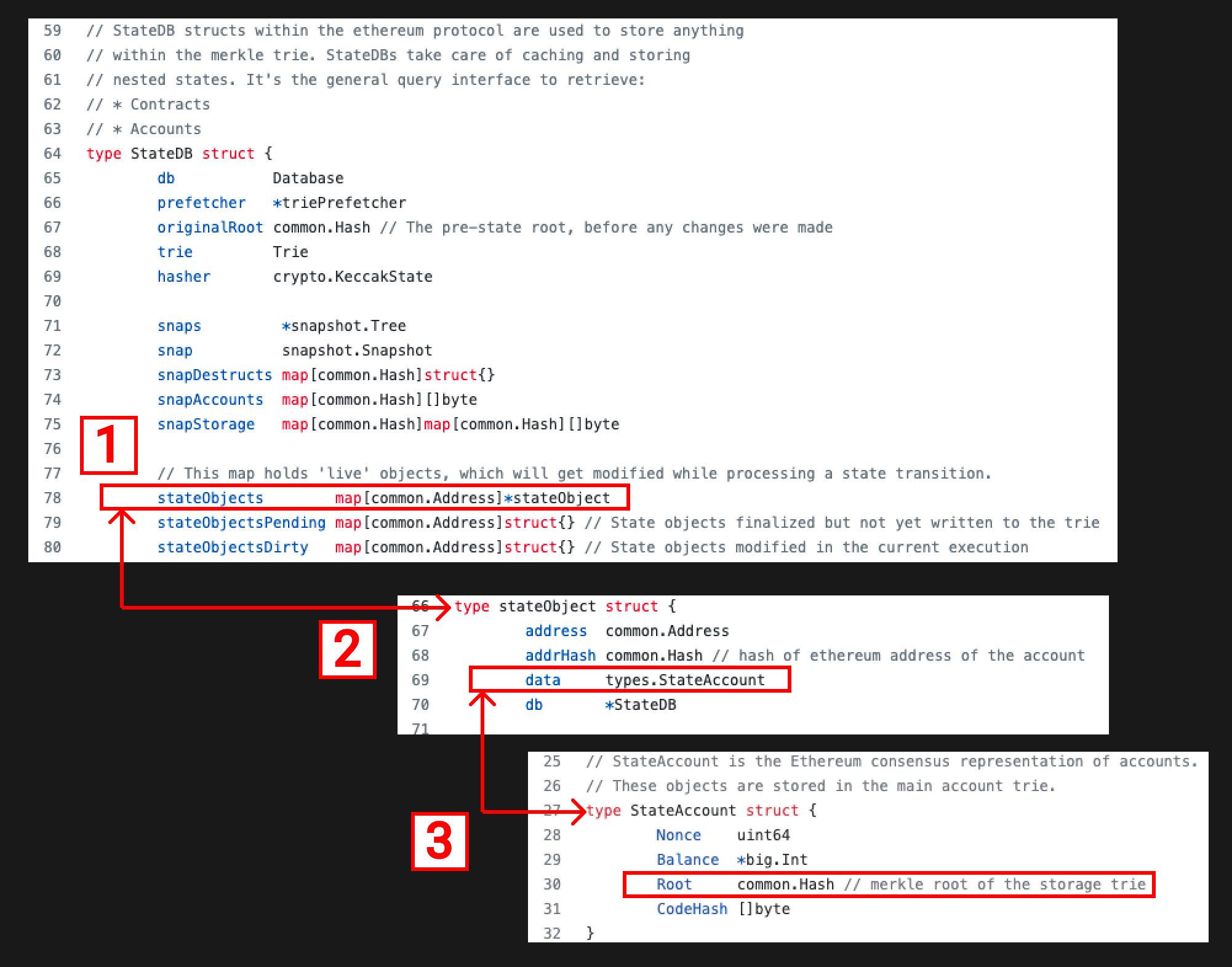
StateDB struct, we can see it has a stateObjects field which is a mapping of addresses to stateObjects (Remember the “State Root” Merkle Patricia Trie was a mapping of Ethereum addresses to Ethereum accounts and that a stateObject is an Ethereum account that is being modified)
stateObject struct, we can see it has a data field which is of type StateAccount (Remember that earlier in the article we mapped an Ethereum account to StateAccount in Geth)
StateAccount struct, we have seen this struct already, it represents an Ethereum account and the Root field represents the “Storage Root” we discussed earlier
At this stage some pieces of the puzzle are starting to fit together. Now we have the context to see how a new “Ethereum account” (StateAccount) is initialised.
Initalising A New Ethereum Account (StateAccount)
To create a new StateAccount we’ll need to interact with the statedb.go file and the StateDB struct.
StateDB has a createObject function which creates a new stateObject and passes a blank StateAccount into it. This is effectively creating a blank “Ethereum account”.
The below diagram details the code flow.

StateDB has a createObject function which takes in a Ethereum address and returns a stateObject (Remember a stateObject represents an Ethereum account that is being modified.)
The createObject function calls the newObject function passing in the stateDB, the address and an empty StateAccount (Remember a StateAccount = Ethereum account) it returns a stateObject
The return statement of the newObject function, we can see there are a number of fields associated with the stateObject, address, data, dirtyStorage etc.
The stateObject data field maps to the empty StateAccount input in the function - Note nil values are replaced in the StateAccount in lines 103 - 111
The stateObject created that contains the initialised StateAccount as a data field is returned
Ok, so we have an empty stateAccount, what do we want to do next?
We want to store some data and to do that we need to use the SSTORE opcode.
SSTORE
Before we dive into the SSTORE implementation in Geth let’s quickly remind ourselves of what SSTORE does.
It pops 2 values off the stack, first the 32-byte key second the 32-byte value and stores that value at the specified storage slot defined by the key.
Below is the Geth code flow for the SSTORE opcode let’s take a look at what it does.
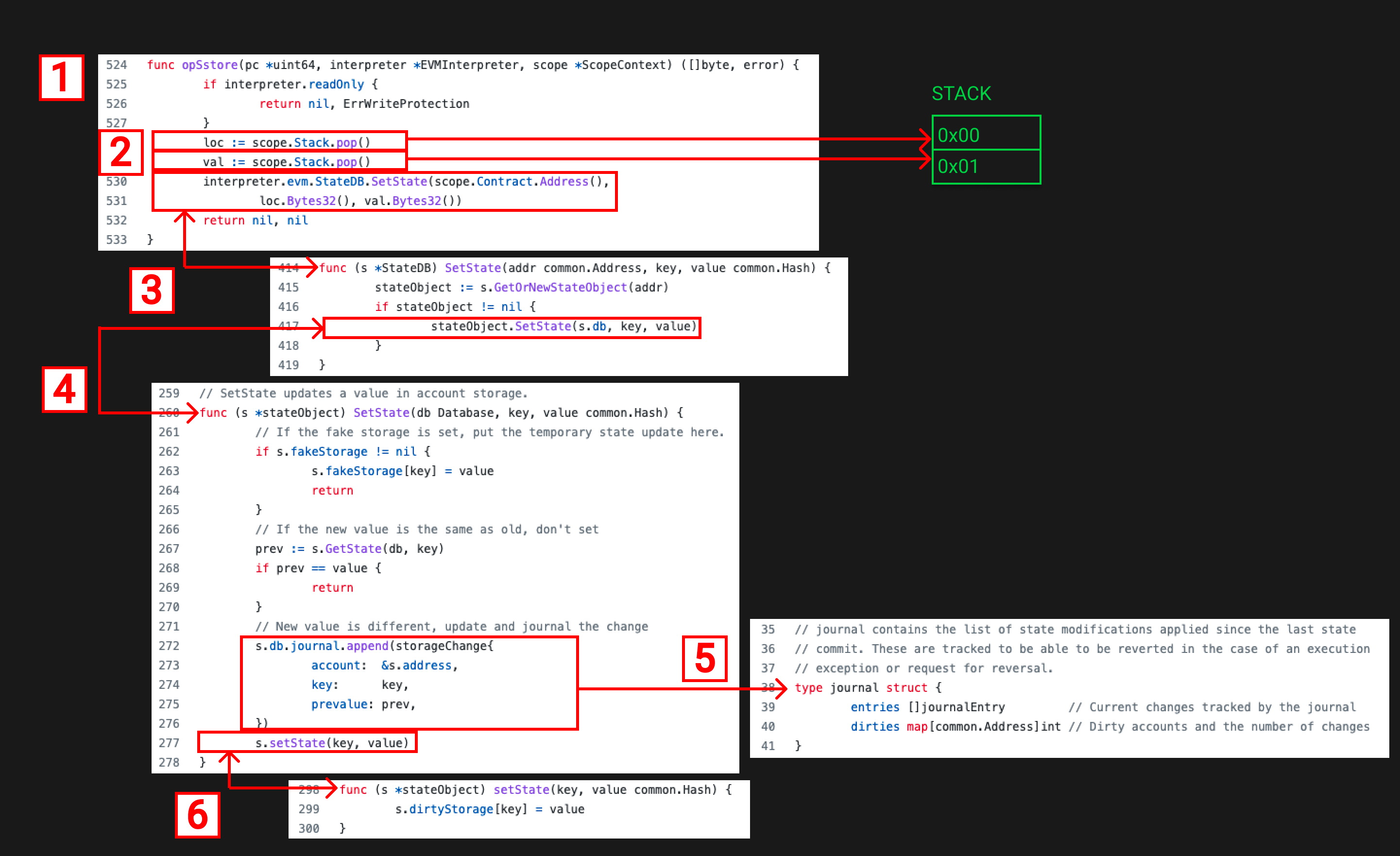
We start with the instructions.go file which defines all the EVM opcodes. Within this file, we find the “opSstore” function.
The scope variable which is passed into the function contains the contract context such as the stack, memory etc. We pop 2 values off the stack and label them loc (short for location) and val (short for value).
The 2 values popped off the stack are then used as inputs along with the contract address for the SetState function associated with the StateDB. The SetState function uses the contract address to check if a stateObject exists for that contract, if it doesn’t it will create one. It then calls SetState on that stateObject passing in the StateDB db, the key and the value.
The stateObject SetState function does some checks on fake storage and whether the value has changed and then runs a journal append.
If you look at the code comment about the journal struct you’ll see that the journal is used to track state modifications so that they can be reverted in the case of an execution exception or request for reversal.
After the journal is updated the storageObject setState function is called with the key and value. This updates the storageObjects dirtyStorage.
Ok, so we have updated the stateObject’s dirtyStorage with the key and value. What does that actually mean and how does it relate to everything we’ve learned so far.
Let’s start with the dirtyStorage definition within the code.

dirtyStorage is defined within the stateObject struct, it is of type Storage and is described as “Storage entries that have been modified in the current transaction execution”
The Storage type which corresponds to dirtyStorage is a simple mapping of common.Hash to common.Hash
The Hash type is simply a byte array of length HashLength
HashLength is a constant defined as 32
This should sound familiar to you a 32-byte key mapping to a 32-byte value. It is exactly how we conceptually viewed contract storage in Part 3 of the EVM Deep Dives.
You may have noticed pendingStorage & originStorage in the stateObject just above the dirtyStorage field. They are all related, during finalisation dirtyStorage is copied across to pendingStorage which in turn is copied across to originStorage when the trie is updated.
After the trie is updated the “Storage Root” of the StateAccount will also be updated during a StateDB “Commit”. This writes the new state to the underlying in-memory trie database.
Now onto the last piece of the puzzle, SLOAD.
SLOAD
Again let’s quickly remind ourselves of what SLOAD does.
It pops 1 value off the stack, the 32-byte key, which represents the storage slot and returns the 32-byte value stored there.
Below is the Geth code flow for the SLOAD opcode let’s take a look at what it does

Again we start with the instructions.go file where we can find the “opSload” function. We grab the location (storage slot) for the SLOAD from the top of the stack using peek.
We call the GetState function on the StateDB passing in the contract address and the storage location. GetState gets the stateObject associated with that contract address. If the stateObject is not nil it calls GetState on that stateObject.
The GetState function on the stateObject does a check on fakeStorage and then does a check on dirtyStorage
If dirtyStorage exists return the value at the key location in the dirtyStorage mapping. (dirtyStorage represents the most up-to-date state of the contract which is why we try to return that first)
Otherwise call the GetCommitedState function to look up the value in the storage trie. Again fakeStorage is checked for.
If pendingStorage exists return the value at the key location in the pendingStorage mapping.
If none of the above have returned go to the originStorage and retrieve & return the value from there.
You’ll have noticed that the function attempted to return dirtyStorage first, then pendingStorage, then originStorage. This makes sense, during execution dirtyStorage is the most up-to-date storage mapping followed by pending and then the originStorage.
One transaction can manipulate a single storage slot multiple times so we must ensure we have the most recent value.
Let’s imagine an SSTORE that happens before an SLOAD on the same slot and in the same transaction. In this situation the dirtyStorage would be updated in the SSTORE and in the SLOAD it would be returned.
There you have it you now have an understanding of how SSTORE & SLOAD are implemented at the Geth client level. How they interact with state & storage objects and how updating a storage slot relates to the wider Ethereum “World State”.
That was intense but you made it. My guess is this article has left you with more questions than you had before you started but that’s part of the fun of crypto.
Keep grinding anon.
noxx
Twitter @noxx3xxon